M y S Q L - Structured Query Language
8. zeilen bearbeiten
8.4 besondersheiten
8.4.1 zeichensatz festlegen
Daten, die in einer DB-tabelle gespeichert werden, stammen aus verschiedenen
quellen;
- aus einer datei, die von der seite eingelesen wird, mit der die zeilen
einer DB-tabelle
erzeugt oder geändert werden;
- aus einem formular, mit dem die daten erfaßt werden;
- direkt aus der seite, mit der die DB-tabelle bearbeitet wird.
Für die speicherung ist der zeichensatz der daten von großer bedeutung. In der regel ist das Ansicode oder Unicode. In der HTML-beschreibung wird ausgeführt, dass der zeichensatz, mit dem eine seite erstellt wird und der zeichensatz, der im header der seite vereinbart wird der gleiche sein sollte (HTML-beschreibung 2.5 und 9.9). Nur so ist eindeutig festgelegt, mit welchem zeichensatz eine seite arbeitet, d.h. daten ausgibt und darstellt. Vertieft wird diese information in der PHP -beschreibung (ziffer 8.9). Bei MySQL kommt jetzt hinzu, dass man festlegen muss, mit welchem zeichensatz die daten in der datenbank gespeichert werden.
vereinbarung im header einer seite
bei HTML4 gibt es folgende anweisung, die heute aaber veraltet ist
<meta http-equiv="Content-Type" content="text/html;
charset=windows-1252 | iso-8859-1 | utf-8">
Ab HTML5 verwendet man:
<meta charset="iso-8859-1 | utf-8">
| windows-1252 iso-8859-1 | Ansicode |
| utf-8 | Unicode |
zeichensatz für datenbank festlegen
Das geschieht mit der anweisung CREATE TABLE (vgl. 7.1)
ENGINE=MyISAM DEFAULT CHARSET=latin1 | utf8
| latin1 | Ansicode |
| utf8 | Unicode |
8.4.2 probleme mit zeichensätzen
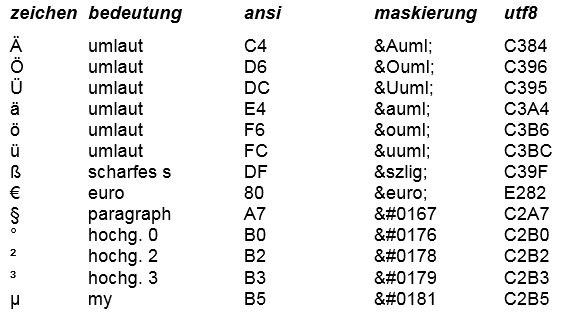
Die beiden zeichensätze Ansicode und Unicode unterscheiden sich nur bei der
codierung von geschlossenen umlauten und einigen sonderzeichen
(?, €, §, °, ², ³, µ); während im Ansicode alle zeichen mit einem byte
verschlüsselt sind, verwendet der Unicode bei den genannten zeichen zwei
bytes. Wenn man konsequent(auch bei den eingabedaten) den gleichen
zeichensatz verwendet, sollte es eigentlich keine probleme geben. Leider
stimmt das nicht, zudem treten die probleme recht uneinheitlich auf, ob das
versions- oder herstellerabhängig ist war nicht zu klären.
probleme mit Unicode
Liegen die daten im Unicode vor und wird dieser zeichensatz auch für die
DB-tabelle vereinbart, gibt es keine probleme, die speziellen zeichen werden
mit zwei bytes gespeichert, seltsamerweis auch dann, wenn man mit der
anweisung Create Table Ansicode vereinbart. Bei der dimensionierung
der spalten muss man natürlich berücksichtigen, dass bestimmte zeichen zwei
bytes platz benötigen. Es gibt nur einen schönheits-fehler: das weit
verbreitete programm für die verwaltung einer datenbank phpmyadmin
stellt die zwei-bytes-zeichen nicht richtig dar, sondern zeigt ziemlich
kryptische zeichenfolgen.
probleme mit Ansicode
Liegen die daten im Ansicode vor, funktioniert es manchmal richtig, selbst
dann, wenn für die datenbank Unicode vereinbart wird. Meist aber geht es
schief, d.h. die o.g. zeichen werden entweder als fragezeichen oder auch
gar nicht gespeichert.
8.4.3 zeichen maskieren
Alle probleme mit den geschlossenen umlauten und den sonderzeichen kann man
umgehen, wenn man diese zeichen maskiert (siehe HTML-beschreibung 2.5).
Allerdings muss man dann die spalten der DB-tabelle entsprechend groß
machen, denn die maskierten zeichen benötigen viel platz, beispielsweise
besteht ein maskiertes Ä aus 6 zeichen: & A u m l ;
codes, maskierung